当サイトはAWS上で稼働させていますが、今までも色々とトラブルはありました。
しかし「EC2が起動できない」という事態は初でした。
「どうするんだ、コレ・・・」状態でしたが、なんとか解決できましたのでメモを残しておきます。
「EC2が起動できない」原因は様々かと思います。
必ずしも当内容で対応できるかは分かりませんので、ご了承ください。
発生事象
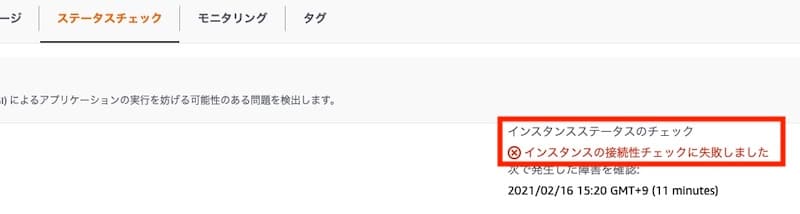
EC2の調子がおかしかったため、EC2のコンソールから「インスタンスを再起動」を実行。
すると、起動時のチェックで「インスタンスの接続性チェックに失敗しました」となり、EC2が起動できず。
SSHで接続することもできません。
発生環境
- AWS EC2
- CentOS8系(KUSANAGI利用)
対応方法
原因の絞り込み
AWSコンソールにて、EC2 > 該当のインスタンス > アクション > モニタリングとトラブルシューティング > システムログを取得
にて、起動時のログが確認できます。
すると、下記のようなエラーが発生していました。
[ 3.948588] No filesystem could mount root, tried: [ 3.954357] Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0)
「Kernel panic」とあるように、どうやらカーネル(OSの核となるプログラム)が壊れているように見えました。
確かに、先日サーバーのモジュールをアップデートしましたが、何かがダメだったのでしょう。
再起動がかかることで、破損が顕在化したものだと思われます。
修復の流れ
カーネルが壊れているのであれば、カーネルを修復すればOKのはず、です。
しかし、そもそもEC2が起動できないため、自力では復旧できません。
そのため、修復手順をザックリとお伝えすると以下になります。
- 破損しているボリュームを、該当のEC2から切り離す(ボリュームをデタッチ)
- 別EC2(レスキュー用EC2)から、そのボリュームに接続(ボリュームをアタッチ)
- レスキュー用EC2でカーネルを修復
- レスキュー用EC2から元EC2にボリュームを戻す
- 元EC2を起動
詳細手順
AWS公式に対処法が掲載されておりました。
そちらに従って実施する形になります。
initramfs またはカーネルモジュールが欠けているため、カーネルをアップグレードするか、Amazon Elasti…

本件のポイントを下記に挙げておきます。
カーネルのバージョンを戻さないとダメだった
今回、カーネルのバージョンを戻さないと起動できませんでした。(最新だとうまく起動しなかった?)
カーネルを戻す手順も、AWS公式に掲載されております。
更新が原因で、Amazon Elastic Compute Cloud (Amazon EC2) インスタンスを再起動で…
カーネルの過去バージョンがボリュームに残っているので、昔のバージョンで起動するように設定してあげるイメージですね。
破損ボリュームのマウントでエラー
手順に従ってもエラーとなりました。
レスキュー用EC2が破損したEC2の(破損前の)コピーであったため、ボリュームのUUID(固有の識別子)が同じであったことが原因と思われます。
一時的にマウントするのみですので、重複を無視する形で接続します。
# エラーになります mount /dev/xvdf1 /mnt #mount: wrong fs type, bad option, bad superblock on /dev/xvdf1, # missing codepage or helper program, or other error # In some cases useful info is found in syslog - try # dmesg | tail or so. # 重複を無視してマウント mount -o nouuid /dev/xvdf1 /mnt
Amazon EBSマウント時にUUIDの重複エラーが発生した時の解決方法を紹介します。…
EC2が起動しなかった時はどうしようかと思いましたが、1つずつ紐解くことでなんとかなりました。
最悪、1週間前くらいのバックアップはありましたが、記事など更新していたため、できるだけ過去断面に戻りたくはなかったというのが本音です。
どこまでバックアップをとりながら運用するか。
これはコストと手間のバランスですね。
※本件は、当運用レベルからすると許容範囲の内容でした。
絶賛配信中!
メルマガ詳細はこちら >>>
広告を含むご案内のメールをお送りする場合があります。
以下も、ぜひご活用ください^^



